6.10.94-stable
In this page
GreyCat Server
Introduction
To empower digital twin, GreyCat is not only a Runtime but also a Server.
Any function can be exposed to remote procedure call (RPC) by just adding an @expose pragma
@expose
fn compute(p: int): int {
return 3 + 5 + p;
}
fn main() {
println(compute(2));
}
This minimal code snippet already define a server (–user=1 deactivate security, more on this later)
greycat serve --user=1
# 10
# INFO 2023-05-25T08:34:21.719127+00:00 GreyCat is serving on port: 8080
# WARN 2023-05-25T08:34:21.719174+00:00 Impersonate mode with user 1
GreyCat server can be queried through an HTTP API, more on this in module 4
The parameters for the endpoint can be url encoded:
curl -X POST -d "[100]" http://localhost:8080/project::compute
> 108
Or the parameters for the endpoint can be JSON encoded:
curl -X POST --json "[100]" http://localhost:8080/project::compute
> 108
If the compute endpoint is also decorated with @json_direct_param, then the curl command becomes:
curl -X POST --json "100" http://localhost:8080/project::compute
> 108
Functions (read vs write mode)
by default, functions are read-only and do not persist their eventual modification to disk
to alter the temporal graph, functions (in fact entrypoint) requires a @write mode pragma
@write also define an exclusive context, and write function can be executed in concurrence
var counter: int?;
@write
@expose
fn inc_count(): int {
counter ?= 0; // initialize at `0` if `null`
counter = counter + 1;
return counter;
}
the following shows that successive calls to the run command persist the state across executions (local or remote)
greycat run inc_count
# 1
greycat run inc_count
# 2
greycat run inc_count
# 3
Functions and error handling
fn sub_process() {
throw "stop here";
}
@expose
fn compute(p: int): int {
sub_process();
return 3 + 5 + p;
}
fn main() {
var res = compute(2);
println(res);
}
in this example sub_process and compute share the error handling management, leading to the following error stack
greycat run
{
"_type":"core.Error",
"code":{"_type":"core.ErrorCode","field":"throw"},
"value":"stop here",
"stack":[
"sub_process (project.gcl:65:23)","compute (project.gcl:69:18)","main (project.gcl:73:26)"
]
}
Function entrypoint == Transaction
every exception thrown activates a rollback mechanism, leaving the temporal graph unchanged
var counter: int?;
@write
@expose
fn inc_count() {
println(counter);
counter ?= 0;
counter = counter + 1;
throw "my bad";
}
this is illustrated in this example, where many calls do not alter the counter due to the following exception
greycat run inc_count
# null
# {"_type":"core.Error","code":{"_type":"core.ErrorCode","field":"throw"},"value":"my bad","stack":["inc_count (project.gcl:70:20)"]}
greycat run inc_count
# null
# {"_type":"core.Error","code":{"_type":"core.ErrorCode","field":"throw"},"value":"my bad","stack":["inc_count (project.gcl:70:20)"]}
Exposed functions are for short computation!
as many API oriented framework, GreyCat adds a timeout to remote function calls (default of 30s, configurable)
@write
@expose
fn heavy_computation() {
while (true) {
// noop
}
}
any call through HTTP API will then result in a timeout exception (therefore rollback)
greycat serve --user=1
curl -X POST http://localhost:8080/project/heavy_computation
# {"_type":"core.Error","code":{"_type":"core.ErrorCode","field":"timeout"},"stack":["heavy_computation (project.gcl:67:15)"]}
timeout is similar for write and read function entrypoint, this enhance the server against multi-user experience
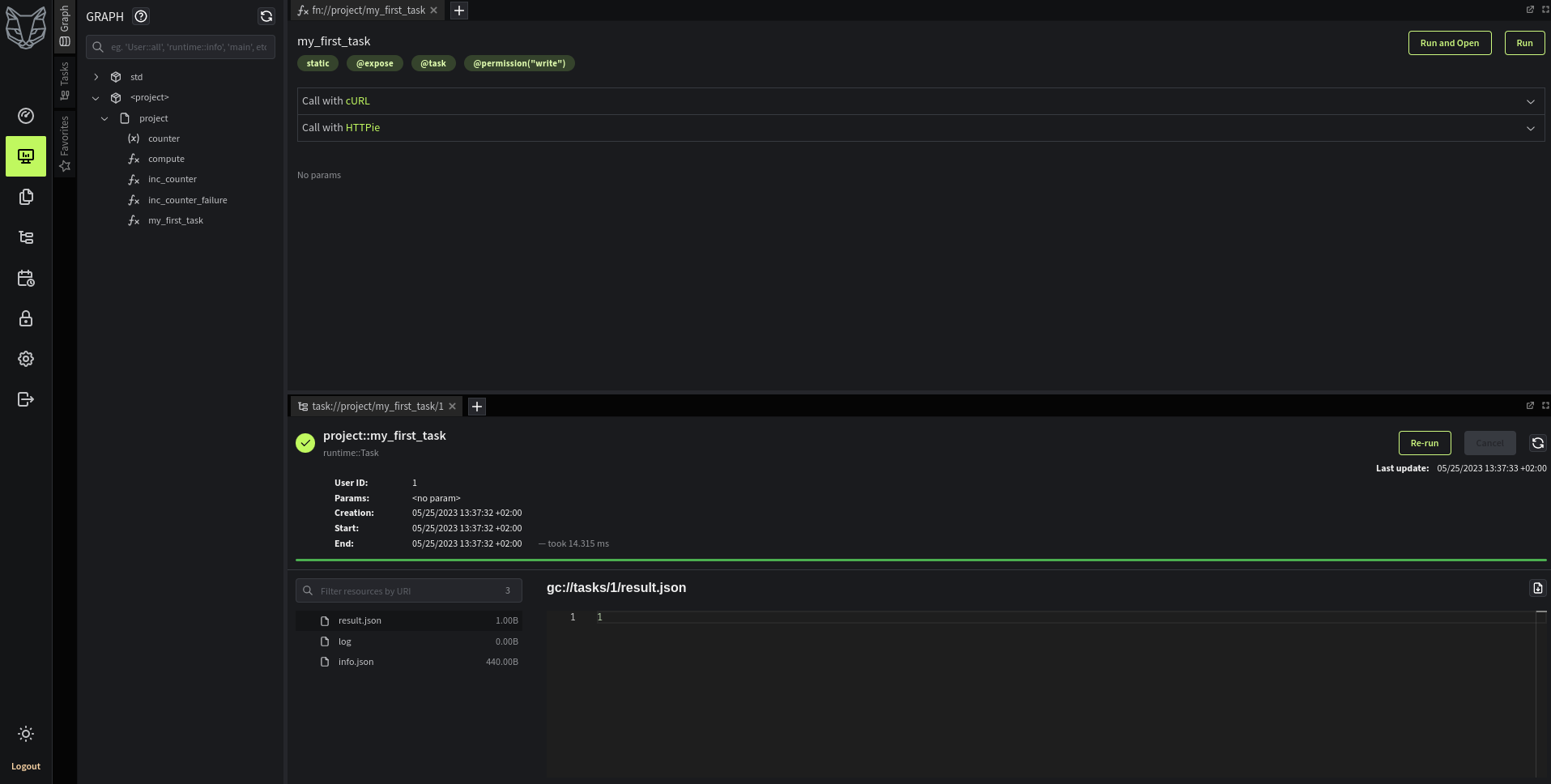
Long running functions? Task is the answer!
for long running transactions GreyCat defines the notion of task
like functions, tasks are transaction units of execution and require @write and @expose for remote usage
@write
@expose
task my_first_task(): int {
counter = (counter ?? 0) + 1;
return counter;
}
tasks can be triggered remotely through HTTP calls, just like functions
curl -X POST http://localhost:8080/project::my_first_task
# 1
however, the task API is asynchronous and remote calls only return an ID
another API exists to get the logs and result regularly
to workaround the extra work of task progress we recommend to use GreyCat Lab tool to track task status
Use progress for long running tasks!
use runtime;
@expose
task long_task() {
for (var i = 0; i < 100; i++) {
Runtime::sleep(100ms);
Task::progress(i);
}
}
Task / error handling
within a task, we can nest sub-tasks and their parameters will be passed by copy
A task will automatically wait for all its children and the progress tracker reports the remaining time
use runtime;
var counter : int?;
@write
task inc_counter() {
counter = (counter ?? 0) + 1;
}
@write
task inc_counter_failure(p: String) {
throw "stop here! ${p}";
}
@write
@expose
task compute() {
Task::spawn("project.inc_counter", []);
Task::spawn("project.inc_counter_failure", ["poison pill"]);
}
however, even when nested, tasks are independent transactions, therefore here the counter is modified at every call
Tasks should be seen as a similar mechanism than MapReduce architecture, the goal is to shard by design