In this page
The nodes of GreyCat
GreyCat is an implementation of a graph structure.
One of its core concepts is therefore the notion of Node that constitute the elements of the graph.
Definition
Nodes are persistent pointers to a location in the Graph, you could think of it as a unique 64-bit ID that you can use to access the content stored on disc.
type Country {
name: String;
phoneCode: int;
location: geo;
fn compute() {
// Does something
}
}
fn main() {
// "luxembourg" object here is in RAM only, not persisted to disk
var luxembourg = Country {
name: "Luxembourg",
phoneCode: 352,
location: geo{49.8153, 6.1296},
};
// In order to store it in the graph, we need to wrap it in a node<Country>
var n_lux = node<Country>{luxembourg};
println(n_lux); // Prints the reference / ID in the graph
}
{“_type”:“core.node”,“ref”:“0100000000000000”}
Congratulations! You created your first node in the GreyCat Graph
Storing value inside nodes will make them persistent but you still need to be able to access them once you leave the scope of the function. This is why in most cases you need to define a module variable that contains all your references.
In the above example you would probably want to store your Country in an nodeIndex, where the country name constitutes the key
var country_by_name = nodeIndex<String, node<Country>>{};
fn main() {
// ...
country_by_name.set(luxembourg.name, n_lux);
}
You can now always access the same instance of n_lux by specifying its name, from anywhere in your application code
var ref = country_by_name.get("luxembourg");
println(ref);
{“_type”:“core.node”,“ref”:“0100000000000000”}
For more information about this consult the section about the graph entrypoint
A Node within GreyCat comprises three primary elements as depicted in the illustration below.
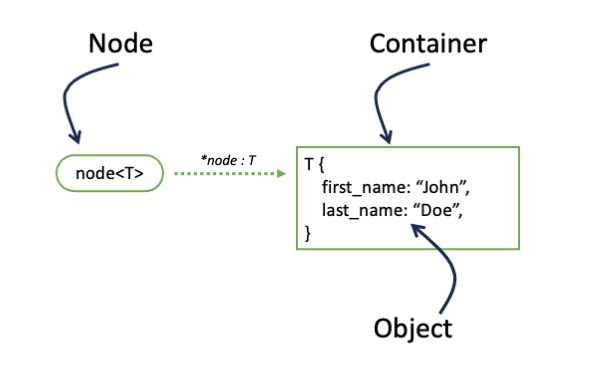
Node can be assimilated to a pointer toward a memory zone. Represented as a pill on the left of the illustration, it is a very lightweight element, a label, used as a handle for a content. It is a sort of unique address or reference of a container in the graph.
Container is a zone in the graph to which the Node is associated. This association is unique and can never be changed. Containers can host anything, from literal values to complex objects, as presented in the illustration.
From a Node, the content of its associated Container can be retrieved using the star (*) prefix, as illustrated by the text above the dotted line. Here again, the mechanism is close to the mechanism of pointers. At the moment of the resolution, if the associated content is not yet available in memory, it will be retrieved from the storage. The operation can therefore be costly. Our advice: resolve only when strictly necessary, and do the resolution only once in case you have loops.
Nodes (or more exactly the Container they are associated with) are typed. The type is specified between < and > symbols. On the illustration is specified that the node is “A node of T”. Meaning that, upon resolving its content, you can expect receiving an Object of type T. If you wanna store a ‘foo’ String in a node of the graph, you would do the following.
var stringNode = node<String>{"foo"};
Resolving the node later would return the value “foo”.
var nodeContent = *stringNode;
Assert::equals("foo", nodeContent);
Objects in GreyCat can only be contained by one and only one container. If you assign an object already contained, to another node, it will throw an error.
For more about this subject look at Ownership
The node reference cannot be retrieved from the content of the container. Said otherwise, the resolution is not bi-directional and only works one way. You can get the content from a node, you cannot get a node from the content.
fn main() {
var luxembourg = Country { name: "Luxembourg", phoneCode: 352, location: geo{49.8153, 6.1296} };
var n_lux = node<Country>{luxembourg};
println(n_lux);
println(n_lux.resolve().name);
println(n_lux->name);
}
- Since a node in GreyCat is just a 64-bits ID in the graph, it needs to be resolved first in order to access the underlying value.
- Instead of calling
.resolve(), you can use the arrow->operator. n_lux->nameis equivalent ton_lux.resolve().name
The arrow notation node->attribute
It can also be used to call methods on the underlying object, take the following example.
fn main() {
// ...
n_lux->compute();
}
Operators Summary
| Operator | Description |
|---|---|
. |
Dot operator, to access fields, attributes and functions on an instance |
:: |
Static access operator, to access static attributes and static functions |
-> |
Arrow operator, Traverses the graph to access an attribute or a function |
Transactions
Changes to the graph will only be committed (stored on disc) after the function execution completes successfully. If an error occurs anywhere inside the function—including within called functions—the entire transaction is rolled back, meaning none of the changes take effect.
var init: node<bool?>;
@expose
fn update_with_fail() {
init.set(true); // Attempt to modify the graph
throw "An Error Occurred"; // This causes the function to fail
}
Here’s what happens step by step:
- The function sets the init node to true, indicating a change in the graph.
- However, immediately after, an error is thrown (throw “An Error Occurred”;).
- Since an error was raised, the entire function fails, and the transaction is not committed.
- As a result, any attempted modifications (like setting init to true) are discarded.
- When accessing init later, it will still return null because the update never actually took effect.
This rollback behavior applies to any error, whether it’s a direct exception in the function or an error from any other function it calls.
Object (heavy) vs Node (light)
What’s the difference between:
type City {
name: String;
country: Country;
}
and
type City {
name: String;
country: node<Country>;
}
??? And which modeling is better ???
The difference between:
type City {
name: String;
// Here every city instance, will embed a full country object
// So if country object is heavy and contains 1000 attributes, object city will be heavier
// since it will contains all country 1000 attributes and the city name attribute
// 2 cities can't have the same country object, since every city object will embed it's own copy
country: Country; // For example Country { name: String, location: geo{6.45, 20.45}, ... }
}
and:
type City {
name: String;
// Here country attribute is an ID of just 64 bits
// Several cities can point to the same country, if they have the same node ref
// Even if the object Country contains 1000 attributes, only a 64 bits ID is stored in the object city
// Using node will make the object lighter because when we load city, we don't need to automatically load the country instance
country: node<Country>; // For example 0x00000001
}
Most of the time it is better to decompose nodes in case they evolve independently!
The logic is similar to how you would structure an SQL Table, In the above example a City belongs to one Country you would also have a different table for the Country and reference that id in the City table, the same logic applies here, All cities point to the same node reference of the country.
Containment and multi-references
There can be circumstances when an element needs to be indexed, or referenced in several places of the graph, to create relationships, sub-groups, handy shortcuts, etc. In that case, as soon as an element needs to be reference (and/or indexed) at least twice, you shall
- Put this element in a dedicated node (container)
- Use the node to index/reference the content.
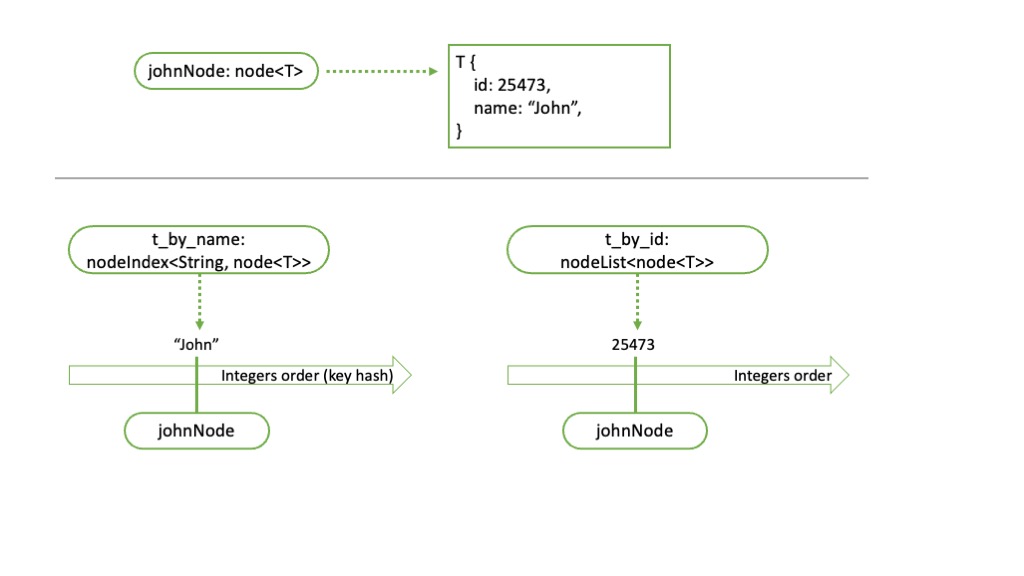
On this illustration, we want to index the element of type T twice, using its name attribute, and using its id attribute. We therefore put this element in its own container, through the usage of a node we name johnNode and reference this node in both our indexes.
var t_by_id = nodeList<node<T>>{};
var t_by_name = nodeIndex<String, node<T>>{};
var johnNode = node<T>::{T { id: 25473, name: "John" }};
t_by_id.set(johnNode->id, johnNode);
t_by_name.set(johnNode->name, johnNode);
Arrow Operator
Used to resolve and access variables inside a GreyCat node:
fn main() {
var nCountry: node<Country> = node<Country>{Country { name: "Luxembourg", phoneCode: 352, location: geo{49.8153, 6.1296}}};
Assert::equals(nCountry->name, "Luxembourg");
}
It is the same as resolving the node and accessing it with the . operator
fn main() {
var nCountry: node<Country> = node<Country>{Country { name: "Luxembourg", phoneCode: 352, location: geo{49.8153, 6.1296}}};
Assert::equals(nCountry->name, (*nCountry).name);
}
Modifying a Nodes content
Primitive values in a node are passed by value where an object is passed by ref.
This becomes important when trying to modify a node’s content.
fn main() {
var nCountry = node<Country>{Country { name: "Luxembourg", phoneCode: 352, location: geo{49.8153, 6.1296}}};
nCountry->name = "Foo"; // arrow operator
var resolved_country = nCountry.resolve(); // resolve first and update the object
resolved_country.name = "Foo";
}
Both methods will permanently modify the object inside the node since when resolving we are working with the object ref itself that is still attached to the node.
On the other hand when using primitives, updating the resolved value will have no effect on the value stored inside the node.
fn main() {
var val_ref = node<int>{ 0 };
var resolved_val = val_ref.resolve();
resolved_val = 5;
print(val_ref.resolve()); // 0
}
Data Structures on nodes
A significant aspect of utilizing a graph involves navigating its elements to locate those of interest. Consequently, having efficient structures to organize the graph’s data is crucial.
Indexes serve this purpose precisely; they are specialized nodes optimized for indexing content. Various types of indexes exist, depending on the nature of the key used to index the elements.
nodeTime
nodeTime aims at indexing elements in the natural order of time. It is the ideal structure to store and manipulate time series. Indeed, a nodeTime
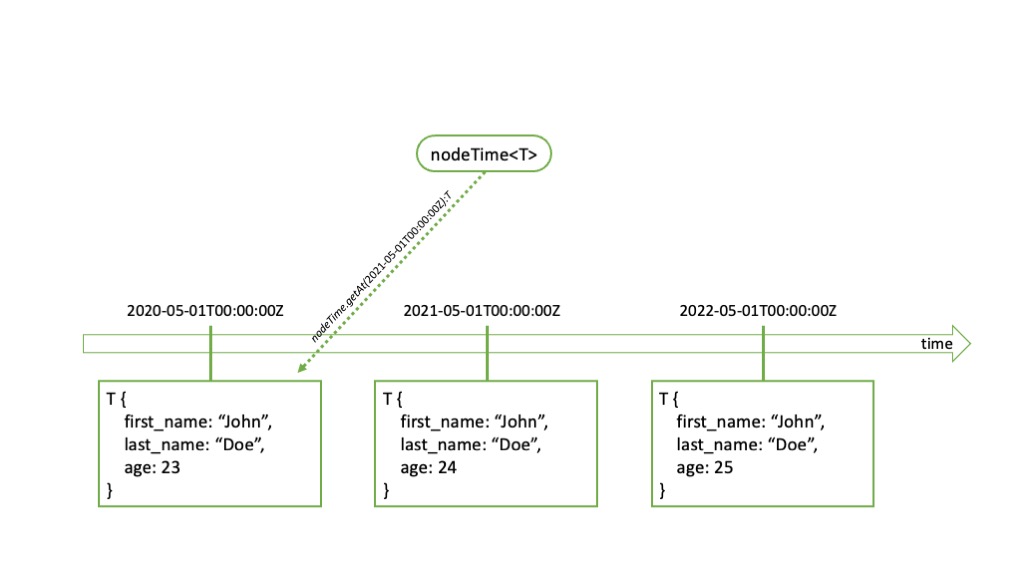
One particularity of the nodeTime is that it takes into account the continuous nature of the time scale. It is therefore completely possible in GreyCat to ask the resolution of an element in between two records. Said otherwise, nodeTime returns the value indexed at a time that is always previous or equal to the time you requested. This mechanism makes it very easy to align various time series and create datasets where all times are aligned.
A nodeTime can be navigated with a simple for loop as follows.
var myTemperature = nodeTime<float>{};
// ... insertion of points
for (t: time, temp: float in myTemperature) {
println("Temperature was ${value} at time ${t}");
}
The loop presented will go through the entire time series, from its first record to the last in the order of time. Filters can be applied using brackets to restrict the temporal period within which records should be navigated
for (t: time, temp: float in myTemperature[fromTime..toTime]) {}
nodeList
nodeList allows indexing elements in the natural order of integers. In this case, the key to index is an integer value of 64 bits.
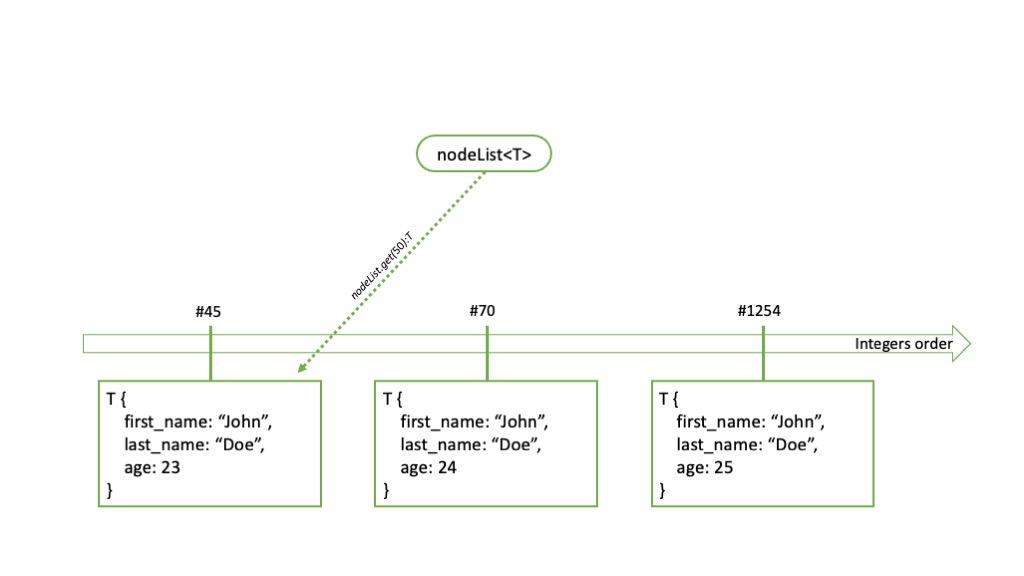
In contrast with the nodeTime, the integer scale being discrete, you must have the exact index to retrieve a specific value. Yet, the nodeList allows to get the first and last elements, and their respective indexes. It is also naturally possible to use for loops to navigate the index.
var myStock = nodeList<Palette>{};
// ... insertion of points
for (position: int, content: Palette in myStock) {
println("Stock location ${position} contains palette ${content}");
}
The loop presented will go through all the positions present in the index, from its first value to the last, in the natural order of integers. Filters can be applied using brackets to restrict the range of integers to be considered. To be noted, the for loop will only iterate on values existing in the index, and will not execute the content of the loop with null for all the integers in the range.
for (position: int, content: Palette in myStock[54..78]) {}
nodeGeo
nodeGeo enables the indexation of elements using a geographical position (latitude and longitude). This comes quite handy when assets need to be localized on a territory.
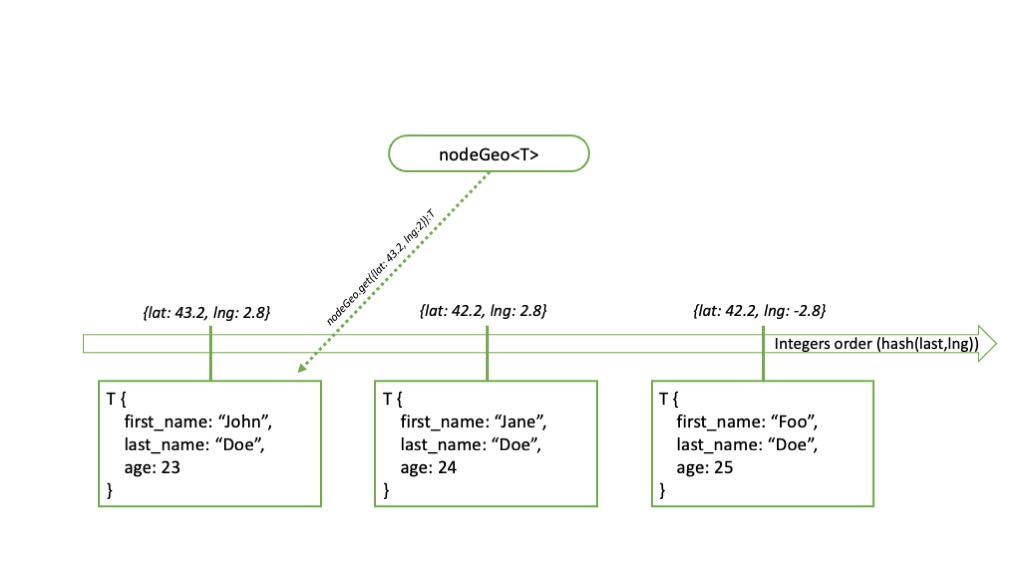
Consistently, the content of nodeGeo can be explored with a for loop.
var myBuildings = nodeGeo<node<Building>>{};
// ... insertion of points
for (position: geo, building: Building in myBuildings) {
println("My building ${building->name} is located at ${position}");
}
nodeIndex
nodeIndex allow the indexation of elements with other kind of keys, that are not time, int, or geo. The key type has to be specified, and the value of the key is hashed to 64 bits unsigned value. It is mostly used to index elements using a String.
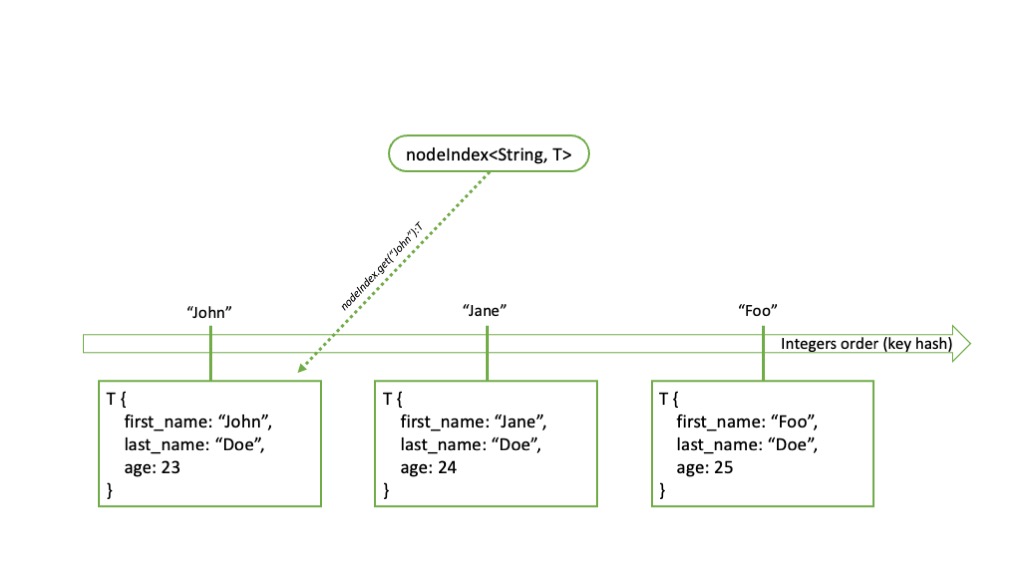
Navigation in this index is also achieved with a for loop going through all elements. There being no meaningful natural order, filters are not available.
var collaboratorsByName = nodeIndex<String, node<Person>>{};
// ... insertion of points
for (name: String, collabNode: node<Person> in collaboratorsByName) {
println("${name} started with us on ${collabNode->start_date}");
}
Sampling nodes
These node structures can very fast reach the millions of values, and for looping them could very fast become slow.
That is why all the above mentioned structures comme with their own static sampling method and accessing them is very similar.
They all accept an array of node, a from and to index, as well as a SamplingMethod, and always return a Table with depending on the SamplingMethod will contain the indexes and node content.
In the case of sampling with nodeTime. We will specify the time range with a beginning and an end time, how many values, in this case 1000, and the method(algorithm) to use.
In the case of nodeTimes you may also specify a maxDephasing and a time zone. We will not specify them in our example.
- maxDephasing: Will set null if the interval between two points is bigger than the indicated
duration.
var result = nodeTime::sample([timeSeries], start, end, 1000, SamplingMode::adaptative, null, null);
SamplingMethods
enum SamplingMode {
// extract elements in range respecting a fixed delta between index values.
// warning this can lead to large result set, defines the bounds with care.
fixed(0);
// extract elements in range respecting a fixed delta between index values.
// in addition to fixed mode, fixed_reg extrapolate numerical values with a linear regression between the previous and next available stored elements to smooth the resulting values.
// warning this can lead to large result set, defines the bounds with care.
fixed_reg(1);
// extract elements in range without respecting a fixed delta between index values.
// in contrary to fixed mode, adaptative mode samples by ensuring a number of skipped elements between the resulting values.
// this mode is useful for none monotonic series where difference between measure are more important than difference between times.
adaptative(2);
// extract all elements between defined ranges, without loosing any elements in between.
dense(3);
}